


The Art of Translation
What if your model could just look where it needed to?

1. The Information Bottleneck
Imagine trying to summarize a book into one single sentence. Every character, plot twist, setting, and emotion encompassed into just one line. Now imagine doing that every time you translate from one language to another. That’s exactly what sequence-to-sequence models did a decade ago. They tried to squeeze entire sentences into a singular fixed-size vector and it worked for short phrases, but not as much for longer ones. Then came a model architecture that rewrote the fundamentals of sequence modeling, and marked on of the most significant changes in the way humans interact with technology and the world today, proposed by Dzmitry Bahdanau et al.1
2. Why This Paper Changed Everything
The paper, Neural Machine Translation by Jointly Learning to Align and Translate, was not just another incremental improvement in machine translation, but rather introduced the first successful attention mechanism, creating a direct lineage to virtually every major breakthrough in modern intelligence. But this begs the question, “What is Attention?"
3. What is Attention?
Before diving into the technical details of my implementation, let's understand what attention is through a simple analogy, our brain. When you're reading this sentence, your brain isn't processing every single word with equal focus. Instead, you're selectively attending to different parts based on what's most relevant at any given moment. Neurologically, a fronto-parietal network (consists of the pre-frontal cortex and the parietal cortex) sends bias signals that boost the firing rates of neurons representing the relevant words and suppress the rest.2
If I ask you "What words were bold in the previous paragraph?", your attention system immediately jumps back to scan for bolded words, ignoring most of the other content, in a way visually re-weighting what you see, amplifying neurons encoding bolded tokens while ignoring everything else.

This selective focus is exactly what attention mechanisms do in neural networks. Instead of forcing a model to remember everything equally, attention allows it to dynamically focus on the most relevant parts of the input when making each prediction.
4. Sequence-to-Sequence Models
Traditional sequence-to-sequence learning (Sutskuver et al.) suffered from a classic Chinese Whispers problem. Whispering a long message from one person to the next through a chain of people, by the time it reaches the end the crucial details are lost through the layers.
In vanilla seq2seq:
Input: "The quick brown fox jumps over the lazy dog"
→ Encoder compresses it to single vector
→ Decoder attempts to reconstruct itThe fixed-size context vector becomes an information bottleneck, especially for longer sequences. Bahdanau attention solved this by allowing the decoder to dynamically look back at different parts of the input sequence, depending on what it’s currently trying to generate.
5. The Bahdanau Attention Mechanism
The intuition behind the Bahdanau Attention mechanism lies behind its simplicity. At each decoding step, instead of solely relying on a fixed context vector, the decoder asks: “Which parts of the input should I pay attention to right now?"
Intuition
Score Calculation: For each decoder step, we calculate how relevant each encoder hidden state is
Attention Weights: We convert these scores into a probability distribution
Context Vector: Based on these probabilities, we create a weighted sum of encoder states
Decoding: We make predictions using this context vector and the previous hidden state
Math
The attention mechanism boils down to three main equations:
Score Function (Energy):
\(e_{ij} = v^T tanh(W_a h_i + U_a s_{j-1})\)
This gives us a “relevance score” between the encoder hidden state and teh decoder’s previous state.
Attention Weights:
\(α_{ij} = softmax(e_{ij})\)
Softmax converts a vector of real numbers into a probability distribution, where each value is between 0 and 1 and the sum of all values equals 1. These are normalized scores (across all encoder states) and the probability distribution tells the model where to focus.
Context Vector
\(c_j = Σ α_{ij} h_i\)
This is the final attention-weighted summary the decoder uses for the current step.
5. Implementation Deep Dive
I’ll now walk you through how I implemented the seq2seq model, the Bahdanau attention mechanism, the dataset I trained the model on, and some results.
Instead of the typical English to French translation problem, I chose code generation as my task. It’s not just pattern matching, but rather requires understanding the intent and translating it into logic that can be executed. When someone says "sort this list in descending order," a model needs to grasp the input, map it to the right Python syntax, and generate syntactically correct code.
Dataset
I used the CoNaLa dataset, which maps natural language descriptions with Python code snippets. The dataset has about 2,400 training examples, which is perfect for experiments. The pre-processing was quite straightforward. I split the text to tokenize the intent and the code and built a shared vocabulary of all the tokens. I added 4 new tokens: <PAD> for padding sequences to equal length, <SOS> to denote the start of a sequence, <EOS> to denote the end and <UNK> for unknown words (outside the vocabulary). During batching, everything gets padded to the maximum length in that batch using <PAD> tokens.
Model
The model follows an encoder-decoder architecture. The encoder is a 2-layer bidirectional LSTM that processes the natural language input. We need to ensure that we skip computations on padding tokens. The bidirectional LSTM outputs are then concatenated.
The decoder is a 2-layer unidirectional LSTM. Without attention, it just takes embeddings as input. With attention, the input dimension increases because I concatenate the embedding with the context vector from the attention mechanism.
The attention mechanism itself implements the Bahdanau additive attention where we have three linear transformations that compute alignment scores between encoder outputs and the current decoder hidden state. For decoder initialization, I take the final bidirectional encoder state, project it down to the decoder's hidden dimension using learned linear layers, then replicate it across decoder layers. This gives the decoder a good starting point that's informed by the entire input sequence.
The forward pass uses teacher forcing – instead of feeding the model's own predictions back as input, I use the ground truth target tokens. This makes training much more stable and faster.
Training Setup
The training setup was very similar to that of the Sequence-to-Sequence paper. I used the SGD optimizer with an initial learning rate of 0.7. I had a learning rate scheduler of sorts where the initial learning rate was the same for the first few epochs, and was halved every half epoch. I clip gradients to a maximum norm of 1.0 to prevent the problem of exploding gradients.
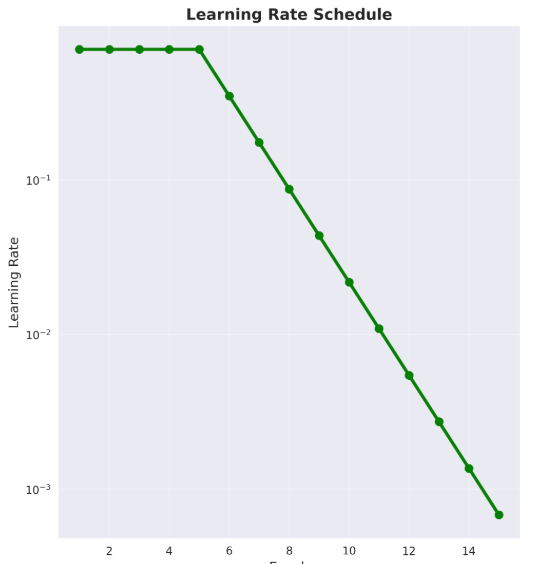
The training loop automatically saves the best model based on validation loss and generates training curves with learning rate schedules. Having those plots made it easy to see that both models were converging properly and the learning rate drops were happening at the right times.
Results
I saw a 0.5% improvement in validation loss using the Bahdanau Attention mechanism versus the baseline architecture.

The improvement is small partly because CoNaLa is a relatively simple dataset. Most examples are short, single-line code snippets where the information bottleneck isn't as severe. On longer, more complex sequences, I'd expect a larger edge for the attention mechanism.
Code
The full implementation is on GitHub at github.com/arnav0811/seq2seq
6. Conclusion
Just as our brain doesn’t process every word in a sentence with equal weightage and instead dynamically alters our focus to what is relevant in that instance, Bahdanau Attention lets models do the exact same thing. It is fascinating how intuitive it feels once you build it. Teaching models where to look at each instance was the key to unlock AI as we know it today.
Thanks for reading! More to come this summer and beyond! I plan to write about the various things I’m learning this summer alongside my other interests.
This is my first blog. I'd genuinely appreciate your honest feedback on what resonated and what could be better.